Survival Analysis of Stroke Patients
Skills
- Survival Analysis
- R
- SAS
- Model Fitting
Introduction
The stroke_data.csv files provides the time until death (in days) for 500 patients following their hospital admission for incidences of stroke. For this analysis, we are interested in whether the rate of death is different between patients who experienced a stroke for the first time and those who have had a recurrent stroke. The number of days from hospital admission to last follow-up, as well as their vital status was recorded. Other variables, such as age, BMI, and year of admission into the hospital were also recorded. The variables (from left to right) are:
ID = Patient ID
lenfol = Days from Hospital Admission Date to Date of Last Follow-up
fstat = Vital Status at Last Follow-up
- 0 - Alive
- 1 - Dead
stroke = Stroke Type
- 0 - First
- 1 - Recurrent
bmi = Body Mass Index
year = Admission Year
- 1 - 1997
- 2 - 1999
- 3 - 2001
age_c = Age at Hospital Admission
- 1 - age < 60
- 2 - 60 ≤ age < 70
- 3 - 70 ≤ age < 80
- 4 - ≥ 80
Model Fitting - SAS
Model 1
We first fit a Cox model with stroke recurrence as the only covariate (Model 1) and examine whether the rate of death is different between patients experiencing stroke for the first time and those experiencing a recurrent stroke at an alpha level of 0.05. The model statement is given below:
Model 1 (Stroke) Statement: ℎ(t,x,B) = h0(t)exp(B1x1) where
x1 = (1 if Recurrent Stroke
0 if First-Time Stroke)
From the SAS output below, we can see that the Wald test statistic is 9.2592; the Pr(x21 ≥9.2592) = 0.0023, which is less than alpha level of 0.05. Thus, at the 5% significance level, we reject the null hypothesis; there is sufficient data on hand to conclude that the rate of death between patients with first time incident stroke and recurrent stroke is statistically different.
Figure 1: SAS Code and Output for Model 1
knitr::include_graphics('images2/strokefig_sas.JPG')
knitr::include_graphics('images2/strokefig.JPG')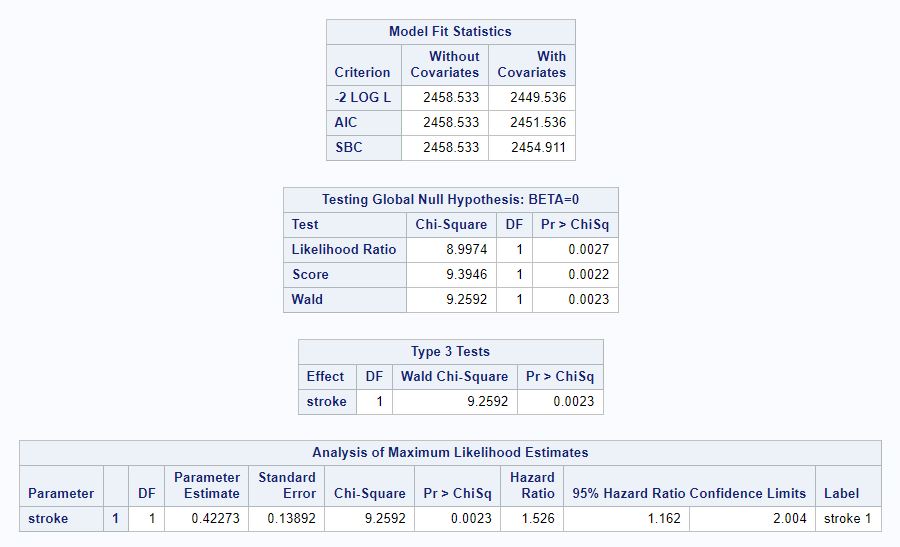
Model 2
We next fit a multivariate Cox model with age, BMI, and admission year as additional covariates. Patients aged less than 60 with first-time strokes admitted to the hospital in 1997 were used as the reference category. The model statement is given below:
Model 2 (Stroke, Age, BMI, Admission Year) Statement: h0(t)exp(B1x1 + B2x2 + B3x3 + B4x4 + B5x5 + B6x6 + B7x7) where
x1 = (1 if Recurrent Stroke
(0 if First-Time Stroke
x2 = (1 if 60 ≤ age < 70
(0 if otherwise
x3 = (1 if 70 ≤ age < 80
(0 if otherwise
x4 = (1 if age ≥ 80
(0 if otherwise
x5 = BMI
x6 = (1 if admission year = 1999
(0 if otherwise
x7 = (1 if if admission year = 2001
(0 if otherwise
From the SAS output below, we can see that the Wald test statistic is 1.2225; the Pr(x27 ≥1.2225) = 0.2689, which is greater than alpha level of 0.05. Thus, at the 5% significance level, we fail to reject the null hypothesis; there is insufficient data on hand to conclude that the rate of death between patients with first time incident stroke and recurrent stroke is statistically different, after adjusting for age, BMI, and admission year.
Figure 2: SAS Code and Output for Model 2
knitr::include_graphics('images2/strokefig2_sas.JPG')
knitr::include_graphics('images2/strokefig2.JPG')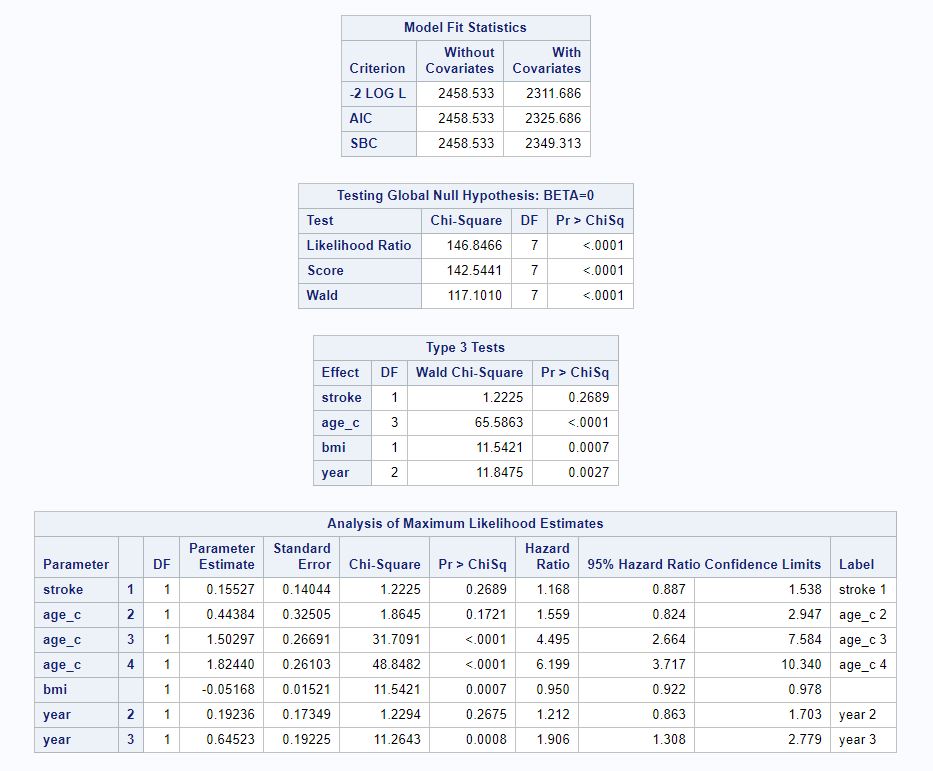
Likelihood Ratio Test
Using the partial likelihood ratios from Model 1 and Model 2, we can determine whether Model 2 is a signficantly better fit than Model 1, by subtracting the partial likelihood for the larger model from that for the smaller model (Figure 3). Pr(x26 ≥ 137.85) < 0.05 (using a chi-squared distribution table) is less than alpha level of 0.05. Thus, at the 5% significance level, there is sufficient data on hand to conclude that Model 2 is a significantly better fit than Model 1.
Figure 3: Testing Model 1 and Model 2 Fit
knitr::include_graphics('images2/model2_lr.JPG')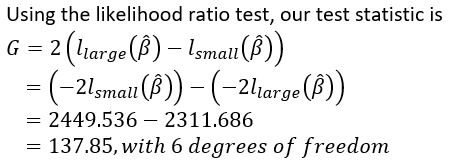
Model 3
We hypothesize that recurrence of stroke varies by age of the patient. Therefore, we now fit a multivariate Cox model with stroke recurrence, age, BMI, admission year as covariates, along with an interaction term between stroke recurrence and age. Again, patients aged less than 60 with first-time strokes admitted to the hospital in 1997 were used as the reference category. The model statement is given below:
Model 3 (Stroke, Age, BMI, Admission Year, StrokexAge) Statement: h0(t)exp(B1x1 + B2x2 + B3x3 + B4x4 + B5x5 + B6x6 + B7x7 + B8x1x2 + B9x1x3 + B10x1x4) where
x1 = (1 if Recurrent Stroke
(0 if First-Time Stroke
x2 = (1 if 60 ≤ age < 70
(0 if otherwise
x3 = (1 if 70 ≤ age < 80
(0 if otherwise
x4 = (1 if age ≥ 80
(0 if otherwise
x5 = BMI
x6 = (1 if admission year = 1999
(0 if otherwise
x7 = (1 if if admission year = 2001
(0 if otherwise
From the SAS output below, we can see that the Wald test statistic is 4.4958; the Pr(x210 ≥4.4958) = 0.034, which is less than alpha level of 0.05. Thus, at the 5% significance level, we reject the null hypothesis; there is sufficient data on hand to conclude that the rate of death between patients with first time incident stroke and recurrent stroke is statistically different, after adjusting for age, BMI, admission year, and an interaction term between stroke recurrence and age.
Figure 4: SAS Code and Output for Model 3
knitr::include_graphics('images2/strokefig3_sas.JPG')
knitr::include_graphics('images2/strokefig3.JPG')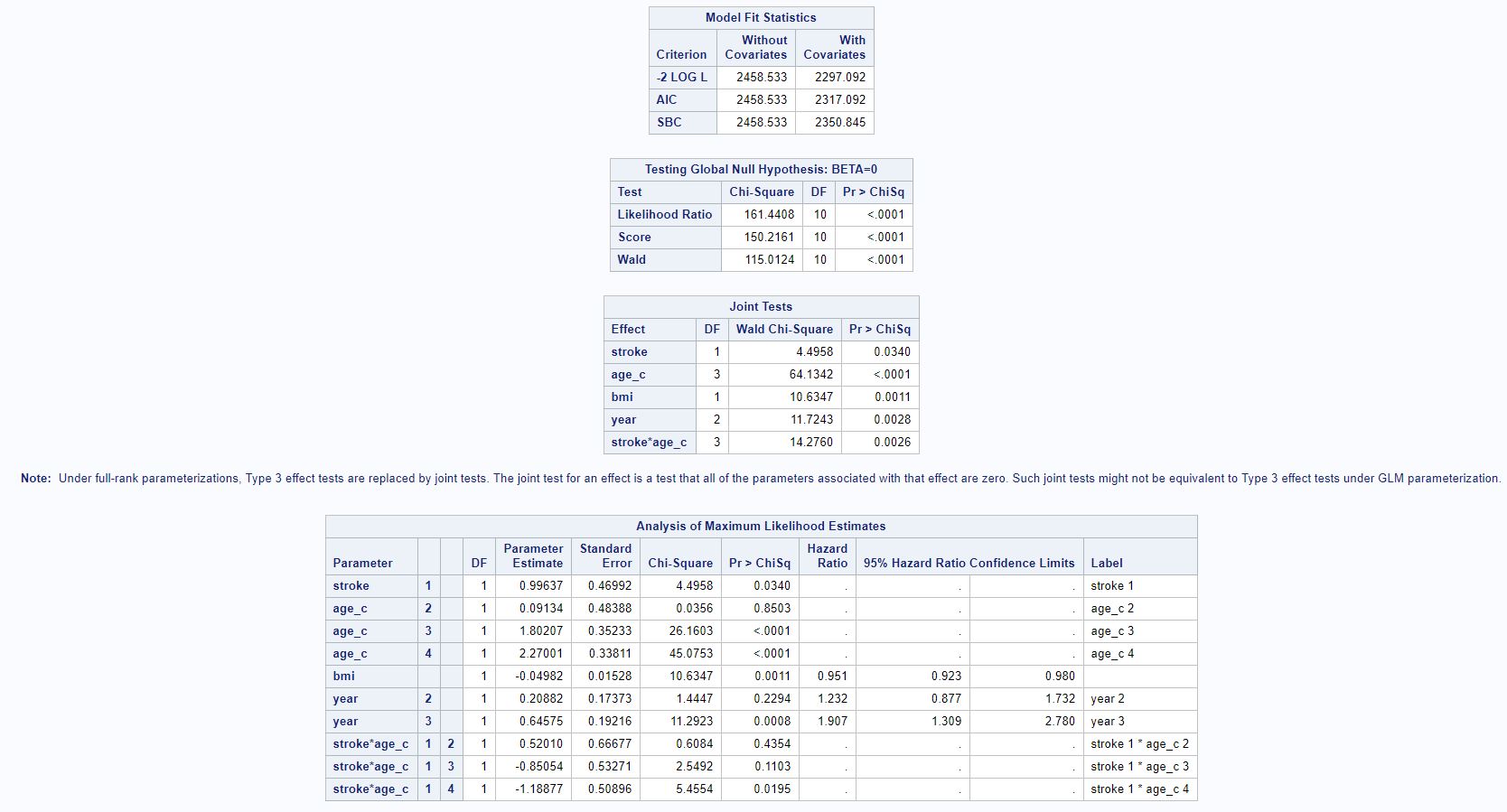
Likelihood Ratio Test
Using the partial likelihood ratios from Model 2 and Model 3, we can determine whether Model 3 is a signficantly better fit than Model 2, by subtracting the partial likelihood for the larger model from that for the smaller model (Figure 5). Pr(x23 ≥ 14.594) < 0.05 (using a chi-squared distribution table) is less than alpha level of 0.05. Thus, at the 5% significance level, there is sufficient data on hand to conclude that Model 3 is a significantly better fit than Model 2.
Figure 5: Testing Model 2 and Model 3 Fit
knitr::include_graphics('images2/model3_lr.JPG')
Testing PH Assumption
Before we proceed with plotting the survival curves and making predictions for certain patients, we quickly check that the proportional hazards assumption holds for Model 3. The SAS output below shows that the predictors in our model meet the PH assumption.
Figure 6: Testing for PH Assumption
knitr::include_graphics('images2/phassume.JPG')
Predictions and Survival Curves
Using Model 3, we can make predict the hazard (i.e., rate) of death for patients with any given covariate.
For example, the estimated hazard ratio for a patient aged 60 to 70 who experienced recurrrent stroke compared to a patient of the same age who experienced stroke for the first time is 4.556 - that is, the rate of death for a patient aged 60 to 70 who experienced recurrent stroke is 4.556 times that for a patient of the same age who experienced stroke for the first time, after controlling for BMI, admission year, and the interaction term between stroke recurrence and age. The SAS code and output are show below.
Figure 7: Hazard Ratio for Stroke = 1 Vs. 0, Age_C = 2
knitr::include_graphics('images2/strokefig4_sas.JPG')
knitr::include_graphics('images2/strokefig4.JPG')
Lastly, we can predict survival curves with our model and estimate the probability of survival after a certain time point (or death up to a given time point). Using the SAS code below, we plot the survival functions of a patient aged 80 or older who experienced recurrent stroke with BMI = 30 admitted in 1997, and a patient aged 80 or older who experienced stroke for the first time with BMI = 30 admitted in 1997.
Figure 8: Survival Curves for Stroke = 1 Vs. 0, Age_C = 4
knitr::include_graphics('images2/strokefig5_sas.JPG')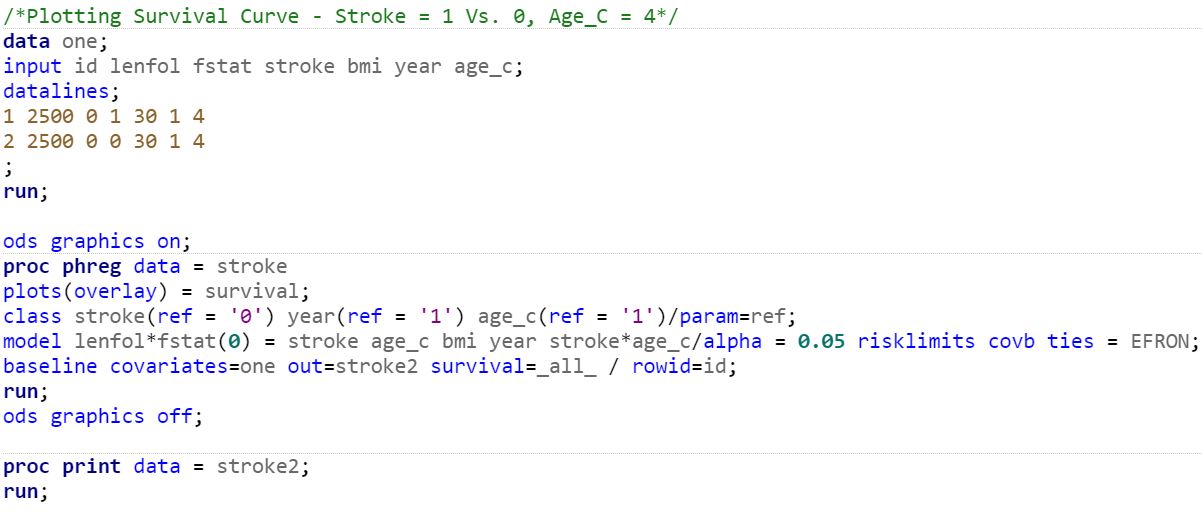
knitr::include_graphics('images2/strokefig5.JPG')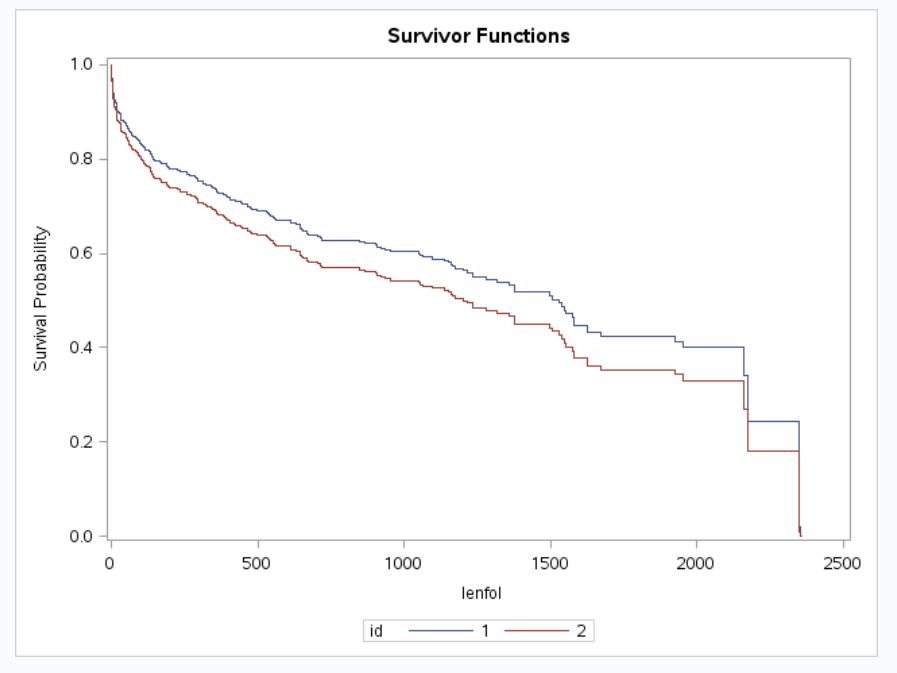
Model Fitting - R
We now try to reproduce our models above using R. We first import the dataset and include the column names. From the output below, we can see that the code successfully imported and tidied the data.
library("survival")## Warning: package 'survival' was built under R version 3.5.3##
## Attaching package: 'survival'## The following object is masked _by_ '.GlobalEnv':
##
## colonlibrary("survminer")## Warning: package 'survminer' was built under R version 3.5.3## Loading required package: ggpubr## Loading required package: magrittr##
## Attaching package: 'magrittr'## The following object is masked from 'package:purrr':
##
## set_names## The following object is masked from 'package:tidyr':
##
## extractlibrary("ggplot2")
library("broom")
library("pixiedust")
stroke <- read.csv("data/stroke_data.csv", header = FALSE)
colnames(stroke) <- (c("id", "lenfol", "fstat", "stroke", "bmi", "year", "age_c"))
knitr::kable(head(stroke))| id | lenfol | fstat | stroke | bmi | year | age_c |
|---|---|---|---|---|---|---|
| 1 | 2178 | 0 | 1 | 25.54051 | 1 | 4 |
| 2 | 2172 | 0 | 0 | 24.02398 | 1 | 1 |
| 3 | 2190 | 0 | 0 | 22.14290 | 1 | 3 |
| 4 | 297 | 1 | 0 | 26.63187 | 1 | 3 |
| 5 | 2131 | 0 | 0 | 24.41255 | 1 | 3 |
| 6 | 1 | 1 | 0 | 23.24236 | 1 | 3 |
Model 1
As shown below, our univariate Cox model gives us identical results to those derived for Model 1 using SAS. The beta coefficient for our stroke variable is 0.4227; exponentiating the value gives us 1.526, indicating that the rate of death for patients who experienced a recurrent stroke is 1.526 times the rate for those who experienced a stroke for the first time. Note that R provided a z test statistic instead of the Wald Chi-Square test statistic derived from Model 1 using SAS; we can square the z test statistic and confirm that the result matches the Wald Chi-Square test statistic. Lastly, the p-value is also identical.
Figure 9: Model 1 Using R
model1 <- coxph(Surv(lenfol, fstat) ~ stroke, data = stroke)
summary(model1)## Call:
## coxph(formula = Surv(lenfol, fstat) ~ stroke, data = stroke)
##
## n= 500, number of events= 216
##
## coef exp(coef) se(coef) z Pr(>|z|)
## stroke 0.4227 1.5260 0.1389 3.043 0.00235 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## exp(coef) exp(-coef) lower .95 upper .95
## stroke 1.526 0.6553 1.162 2.004
##
## Concordance= 0.54 (se = 0.017 )
## Rsquare= 0.018 (max possible= 0.993 )
## Likelihood ratio test= 9 on 1 df, p=0.003
## Wald test = 9.26 on 1 df, p=0.002
## Score (logrank) test = 9.39 on 1 df, p=0.002Model 2
We next fit a multivariate Cox model with age, BMI, and admission year as additional covariates. We include “factor” in our code for any multi-level categorical variables; note that we also have the option of changing our reference category for any categorical predictors by using relevel(factor( ), ref = ' ').
From the R output below, we can see that the z test statistic is 1.106; the Pr(|z| ≥1.106) = 0.2689, which is greater than alpha level of 0.05. Thus, at the 5% significance level, we fail to reject the null hypothesis; there is insufficient data on hand to conclude that the rate of death between patients with first time incident stroke and recurrent stroke is statistically different, after adjusting for age, BMI, and admission year. These results are identical to those derived from Model 2 using SAS. Note that the likeihood ratio test results provided below only test whether the current model is a better fit than the null model.
Figure 10: Model 2 Using R
model2 <- coxph(Surv(lenfol, fstat) ~ stroke + factor(age_c) + bmi + factor(year), data = stroke)
summary(model2)## Call:
## coxph(formula = Surv(lenfol, fstat) ~ stroke + factor(age_c) +
## bmi + factor(year), data = stroke)
##
## n= 500, number of events= 216
##
## coef exp(coef) se(coef) z Pr(>|z|)
## stroke 0.15527 1.16797 0.14043 1.106 0.26888
## factor(age_c)2 0.44417 1.55919 0.32507 1.366 0.17182
## factor(age_c)3 1.50327 4.49637 0.26694 5.632 1.79e-08 ***
## factor(age_c)4 1.82475 6.20126 0.26106 6.990 2.75e-12 ***
## bmi -0.05168 0.94964 0.01521 -3.397 0.00068 ***
## factor(year)2 0.19237 1.21211 0.17349 1.109 0.26752
## factor(year)3 0.64523 1.90643 0.19225 3.356 0.00079 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## exp(coef) exp(-coef) lower .95 upper .95
## stroke 1.1680 0.8562 0.8869 1.5381
## factor(age_c)2 1.5592 0.6414 0.8245 2.9485
## factor(age_c)3 4.4964 0.2224 2.6647 7.5871
## factor(age_c)4 6.2013 0.1613 3.7176 10.3442
## bmi 0.9496 1.0530 0.9217 0.9784
## factor(year)2 1.2121 0.8250 0.8627 1.7030
## factor(year)3 1.9064 0.5245 1.3079 2.7788
##
## Concordance= 0.732 (se = 0.017 )
## Rsquare= 0.254 (max possible= 0.993 )
## Likelihood ratio test= 146.8 on 7 df, p=<2e-16
## Wald test = 117.1 on 7 df, p=<2e-16
## Score (logrank) test = 142.5 on 7 df, p=<2e-16Model 3
We hypothesize that recurrence of stroke varies by age of the patient. Therefore, we now fit a multivariate Cox model with stroke recurrence, age, BMI, admission year as covariates, along with an interaction term between stroke recurrence and age. From the R output below, we can see that the z test statistic is 2.12; the Pr(|z| ≥2.12) = 0.034, which is less than alpha level of 0.05. Thus, at the 5% significance level, we reject the null hypothesis; there is sufficient data on hand to conclude that the rate of death between patients with first time incident stroke and recurrent stroke is statistically different, after adjusting for age, BMI, admission year, and an interaction term between stroke recurrence and age. The rate of death for those experiencing a recurrent stroke is 2.7085 times the rate of death for those experiecing a first-time stroke, after adjusting for age, BMI, admission year, and an interaction term between stroke recurrence and age.
Figure 11: Model 3 Using R
model3 <- coxph(Surv(lenfol, fstat) ~ stroke + factor(age_c) + bmi + factor(year) + stroke*factor(age_c), data = stroke)
summary(model3)## Call:
## coxph(formula = Surv(lenfol, fstat) ~ stroke + factor(age_c) +
## bmi + factor(year) + stroke * factor(age_c), data = stroke)
##
## n= 500, number of events= 216
##
## coef exp(coef) se(coef) z Pr(>|z|)
## stroke 0.99638 2.70847 0.46992 2.120 0.033978 *
## factor(age_c)2 0.09135 1.09565 0.48388 0.189 0.850257
## factor(age_c)3 1.80208 6.06225 0.35233 5.115 3.14e-07 ***
## factor(age_c)4 2.27002 9.67956 0.33811 6.714 1.90e-11 ***
## bmi -0.04982 0.95140 0.01528 -3.261 0.001110 **
## factor(year)2 0.20882 1.23223 0.17373 1.202 0.229373
## factor(year)3 0.64575 1.90741 0.19216 3.360 0.000778 ***
## stroke:factor(age_c)2 0.52010 1.68219 0.66678 0.780 0.435381
## stroke:factor(age_c)3 -0.85055 0.42718 0.53271 -1.597 0.110344
## stroke:factor(age_c)4 -1.18878 0.30459 0.50896 -2.336 0.019507 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## exp(coef) exp(-coef) lower .95 upper .95
## stroke 2.7085 0.3692 1.0783 6.8033
## factor(age_c)2 1.0957 0.9127 0.4244 2.8285
## factor(age_c)3 6.0622 0.1650 3.0390 12.0931
## factor(age_c)4 9.6796 0.1033 4.9895 18.7783
## bmi 0.9514 1.0511 0.9233 0.9803
## factor(year)2 1.2322 0.8115 0.8766 1.7321
## factor(year)3 1.9074 0.5243 1.3088 2.7798
## stroke:factor(age_c)2 1.6822 0.5945 0.4553 6.2149
## stroke:factor(age_c)3 0.4272 2.3409 0.1504 1.2135
## stroke:factor(age_c)4 0.3046 3.2831 0.1123 0.8259
##
## Concordance= 0.743 (se = 0.017 )
## Rsquare= 0.276 (max possible= 0.993 )
## Likelihood ratio test= 161.4 on 10 df, p=<2e-16
## Wald test = 115 on 10 df, p=<2e-16
## Score (logrank) test = 150.2 on 10 df, p=<2e-16Testing PH Assumption
We run the code below to see of the PH assumption is violated. Since p-values are above 0.05, this indicates that the PH assumption was not violated.
Figure 12: Testing PH Assumption
cox.zph(model3)## rho chisq p
## stroke 0.0282 0.1733 0.677
## factor(age_c)2 -0.0264 0.1517 0.697
## factor(age_c)3 -0.0107 0.0264 0.871
## factor(age_c)4 0.0434 0.4314 0.511
## bmi 0.0622 1.0490 0.306
## factor(year)2 0.0270 0.1660 0.684
## factor(year)3 0.0741 1.2837 0.257
## stroke:factor(age_c)2 0.0308 0.2041 0.651
## stroke:factor(age_c)3 0.0467 0.4800 0.488
## stroke:factor(age_c)4 -0.0592 0.7688 0.381
## GLOBAL NA 10.6768 0.383Predictions and Survival Curves
Below, I plot the average survival curve for the patients (by default, covariates are assigned mean values).
Figure 13: Average Survival Curve
ggsurvplot(survfit(model3), data = stroke, ylab = "Survival Probability", title = "Model 3 - Survival Curve",
palette = c("#075CA7"), ggtheme = theme_classic2(), legend = "bottom")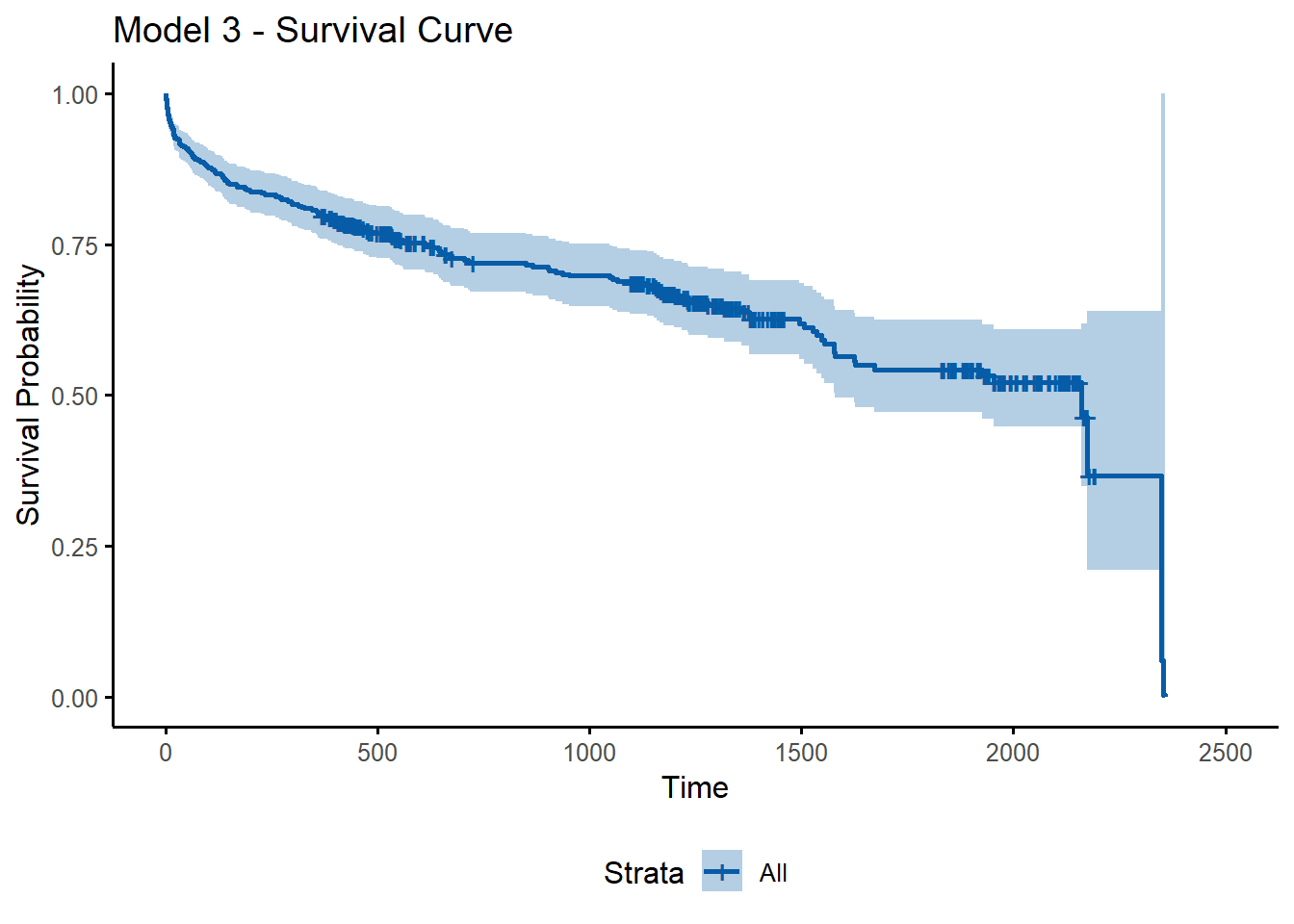
Lastly, we can predict survival curves with our model and estimate the probability of survival after a certain time point (or death up to a given time point). Using the R code below, we plot the survival functions of a patient aged 80 or older who experienced recurrent stroke with BMI = 30 admitted in 1997, and a patient aged 80 or older who experienced stroke for the first time with BMI = 30 admitted in 1997. Note that you can use the code summary(newmodel) to view the median survival times shown in the plot below (as well as other survival probabilities); for SAS, the equivalent code above would be proc print data = stroke2; run (Figure 8).
new_df <- with(stroke, data.frame(id = c(1, 2),
fstat = c(1, 2),
stroke = c(1, 0),
bmi = c(30, 30),
year = c(1, 1),
age_c = c(4, 4)))
new_df## id fstat stroke bmi year age_c
## 1 1 1 1 30 1 4
## 2 2 2 0 30 1 4newmodel <- survfit(model3, newdata = new_df, data = stroke)
ggsurvplot(newmodel, conf.int = FALSE, palette = c("#075CA7", '#ff0000'), surv.median.line = "hv", legend.labs = c("ID=1", "ID=2"), ylab = "Survival Probability", title = "Survival Curves for Two Patients")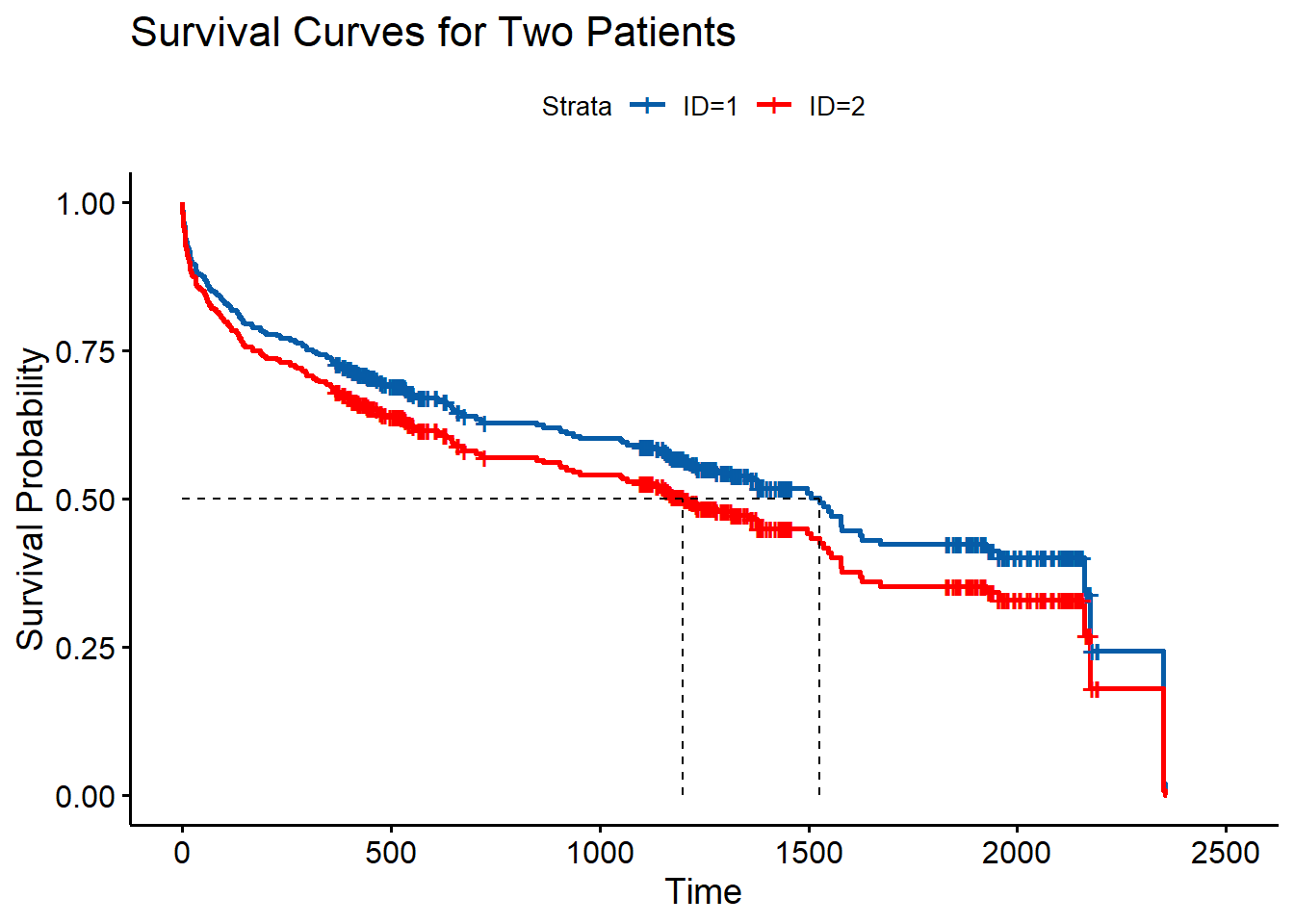
𝑟𝑤𝑖𝑠𝑒