Differences in Mean Length of NYC Felonies
Skills
- Data Analysis
- ANOVA
- R
- Statistical Analysis
Introduction
In the “Exploring NYC Crime Data Using EDA” exploratory data analysis, we found that the average length of time of reported crime (i.e., time between when it started and when it ended) differed by felony type (sex-related, drug-related, and weapons-related), as well as by borough in NYC.
We now want to test whether these differences are statistically significant. Testing this difference can yield important insights regarding whether there is a disproportionate amount of felonies occurring in a certain borough. Finding a significant result may also suggest that certain felonies are more extensive and complicated, potentially more dangerous or violent, or may require more resources to deal with. Lastly, it may indicate that certain types of victims (e.g., victims of sex trafficking) are at a higher risk compared to those involved in other types of felonies.
Data and Methods
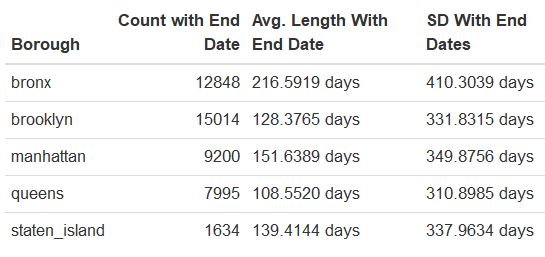
Results from the exploratory data analysis are included below. We notice that sex-related felonies last the longest, on average; compared to the other boroughs, Bronx reports the longest felonies, on average. Note that this statistical analysis uses data with missing end dates inputted as the last day of 2017, which was the last year of recorded data. Also, we used Manhattan as the reference borough and drug-related felonies as the reference felony.
Figure 1: Mean Length of Felonies by Crime Group
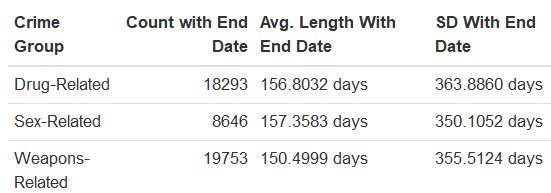
Figure 2: Mean Length of Felonies by Borough
See the exploratory data analysis project related to this for fuller details regarding how the data were cleaned.
Results
Differences by Felony Type
We first test whether there is a difference in average length of crime by felony. Since we are testing the difference in means between three groups, we can conduct an ANOVA test. To ensure that the assumptions of the ANOVA test are not violated, we first test for homogeneity of variances. We used Levene’s test to test homogeneity of variances. We see from the results below that the p-value is greater than 0.05. Therefore, the assumption of homogenous variances is met.
time_data$time_diff2 <- as.numeric(time_data$time_diff2)
leveneTest(time_diff2 ~ crime_group, data = time_data) %>%
broom::tidy() %>%
knitr::kable()| term | df | statistic | p.value |
|---|---|---|---|
| group | 2 | 1.876591 | 0.1531227 |
| 46689 | NA | NA |
We can now proceed to use the ANOVA test. The results indicate that the p-value is greater than 0.05; thus, we have insufficient data to conclude that at least one of the mean lengths of crime differ by felony type.
anova <- aov(time_diff2 ~ crime_group, data = time_data)
broom::tidy(anova)## # A tibble: 2 x 6
## term df sumsq meansq statistic p.value
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 crime_group 2 480567. 240284. 1.88 0.153
## 2 Residuals 46689 5978184131. 128043. NA NADifferences by Borough
We now test whether there is a difference in average length of crime by borough. Again, to ensure that the assumptions of the ANOVA test are not violated, we first test for homogeneity of variances. We used Levene’s test to test homogeneity of variances. We see from the results below that the p-value is less than 0.05. Therefore, the assumption of homogenous variances is not met.
time_data$time_diff2 <- as.numeric(time_data$time_diff2)
leveneTest(time_diff2 ~ boro_nm, data = time_data) %>%
broom::tidy() %>%
knitr::kable()| term | df | statistic | p.value |
|---|---|---|---|
| group | 4 | 152.4968 | 0 |
| 46686 | NA | NA |
We resort to using a non-parametric approach in detecting a difference of means among these five boroughs by utilizing the Kruskal-Wallis test. From the test below, we can see that the p-value is less that 0.05. We conclude that at the 5% level of significance, at least one of the average lengths of reported crimes (i.e., time between when the crime started and when it ended) is different among the five boroughs.
kruskal.test(time_diff2 ~ boro_nm, data = time_data) %>%
broom::tidy() %>%
knitr::kable()| statistic | p.value | parameter | method |
|---|---|---|---|
| 646.7241 | 0 | 4 | Kruskal-Wallis rank sum test |
Since the Kruskal–Wallis test is significant, we now conduct a post-hoc analysis to determine which boroughs differ from each other. We use the Dunn test for the post-hoc analysis. From the test below, we can clearly see that the average length of felony is statistically different from borough to borough, except when you compare 1) Staten Island and Manhattan and 2) Staten Island and Brooklyn.
dunn.test(time_data$time_diff2, time_data$boro_nm, method = "bonferroni")## Kruskal-Wallis rank sum test
##
## data: x and group
## Kruskal-Wallis chi-squared = 646.7241, df = 4, p-value = 0
##
##
## Comparison of x by group
## (Bonferroni)
## Col Mean-|
## Row Mean | bronx brooklyn manhatta queens
## ---------+--------------------------------------------
## brooklyn | 21.58242
## | 0.0000*
## |
## manhatta | 12.68001 -6.510852
## | 0.0000* 0.0000*
## |
## queens | 21.69130 3.582797 8.882338
## | 0.0000* 0.0017* 0.0000*
## |
## staten_i | 8.359785 -1.528450 1.727960 -3.293653
## | 0.0000* 0.6320 0.4200 0.0049*
##
## alpha = 0.05
## Reject Ho if p <= alpha/2Discussion
The results show that the average length of reported crimes does not statistically differ by felony type (p = 0.153). However, when we examine all felony types by borough, we notice that the average length of reported crimes does statistically differ by borough - we found statistical differences for each borough-borough comparison, except when comparing 1) Staten Island and Manhattan and 2) Staten Island and Brooklyn. All together, we do not have evidence suggesting that sex-related, weapons-related, or drug-related felonies have different mean lengths of crime; however, we have sufficient evidence to conclude that the length of felonies vary by borough, with the longest felonies occuring in the Bronx.